TL;DR: We present GeFu, a generalizable NeRF method that synthesizes novel views from multi-view images in a single forward pass.
Abstract
Generalizable NeRF aims to synthesize novel views for unseen scenes. Common practices involve constructing variance-based cost volumes for geometry reconstruction and encoding 3D descriptors for decoding novel views. However, existing methods show limited generalization ability in challenging conditions due to inaccurate geometry, sub-optimal descriptors, and decoding strategies. We address these issues point by point. First, we find the variance-based cost volume exhibits failure patterns as the features of pixels corresponding to the same point can be inconsistent across different views due to occlusions or reflections. We introduce an Adaptive Cost Aggregation (ACA) approach to amplify the contribution of consistent pixel pairs and suppress inconsistent ones. Unlike previous methods that solely fuse 2D features into descriptors, our approach introduces a Spatial-View Aggregator (SVA) to incorporate 3D context into descriptors through spatial and inter-view interaction. When decoding the descriptors, we observe the two existing decoding strategies excel in different areas, which are complementary. A Consistency-Aware Fusion (CAF) strategy is proposed to leverage the advantages of both. We incorporate the above ACA, SVA, and CAF into a coarse-to-fine framework, termed Geometry-aware Reconstruction and Fusion-refined Rendering ( GeFu ). GeFu attains state-of-the-art performance across multiple datasets.
Method
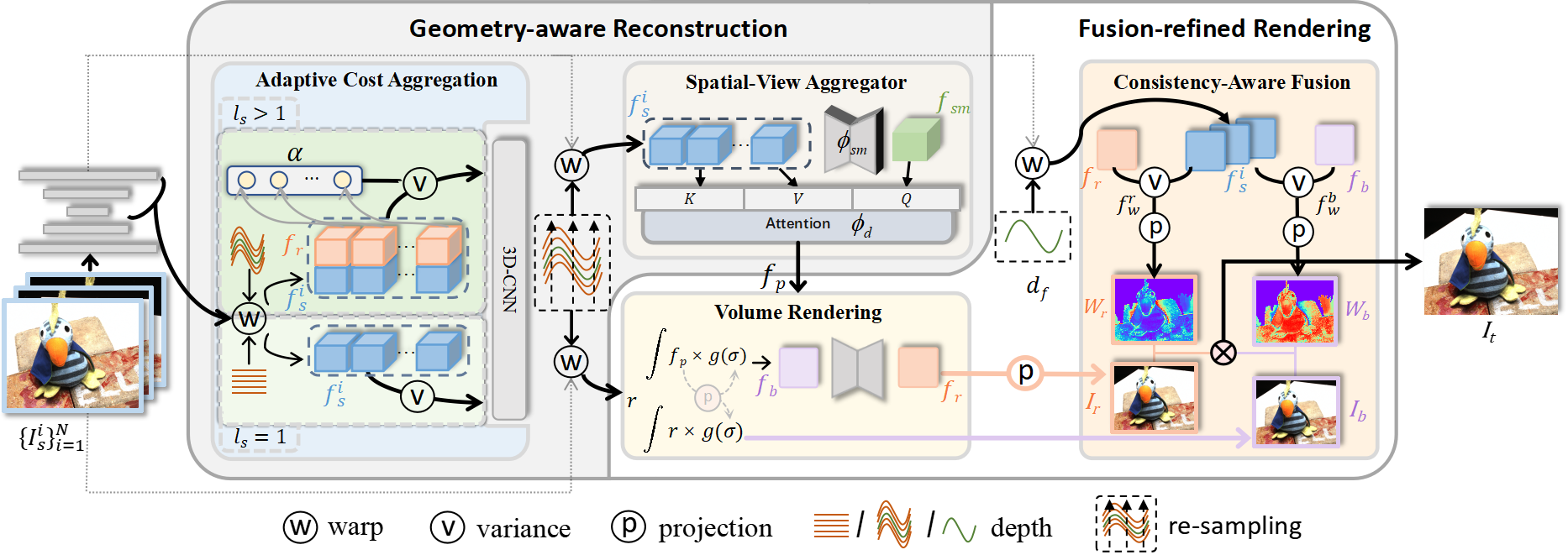
The overview of GeFu. In the reconstruction phase, we first infer the geometry from the constructed cost volume, and the geometry guides us to further re-sample 3D points around the surface. For each sampled point, the warped features from source images are aggregated and then fed into our proposed Spatial-View Aggregator (SVA) to learn spatial and inter-view context-aware descriptors fp. In the rendering phase, we apply two decoding strategies to obtain two intermediate views and fuse them into the final target view in an adaptive way, termed Consistency-Aware Fusion (CAF). Our pipeline adopts a coarse-to-fine architecture, the geometry from the coarse stage (ls=1) guides the sampling at the fine stage (ls>1), and the features from the coarse stage are transferred to the fine stage for ACA to improve geometry estimation. Our network is trained end-to-end using only RGB images.
Demo Video
Generalization results

Depths
Finetuned results
DTU
Real Forward-facing
NeRF Synthetic
BibTeX
@InProceedings{Liu_2024_CVPR,
author = {Liu, Tianqi and Ye, Xinyi and Shi, Min and Huang, Zihao and Pan, Zhiyu and Peng, Zhan and Cao, Zhiguo},
title = {Geometry-aware Reconstruction and Fusion-refined Rendering for Generalizable Neural Radiance Fields},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
pages = {7654-7663}
}
